【摘要】
随着大语言模型(LLM)技术的快速迭代,推理能力作为衡量模型智能水平的核心指标,已成为学术界与产业界的研究焦点。现有关于LLM推理能力的评测多聚焦于特定任务(如数学推理、逻辑能力),缺乏覆盖多维推理场景的系统框架,难以全面反映模型在实际应用中的推理效能。
为应对上述挑战,本研究构建了一套系统、客观、公正的人工智能模型推理能力评价体系。我们在中文语境下针对纯文本推理的评测显示,GPT-03在基础逻辑能力测评上以高分登顶,Gemini 2.5 Flash在情境推理能力测评中拔得头筹;在综合能力排名上,豆包1.5 Pro(思考模式)排名首位,Open Al近日推出的GPT-5(自动模式)紧随其后,豆包1.5 Pro、DeepSeek-R1、以及通义千问3(思考模式)在内的多款国产LLM也均排人前列,展现了国产LLM在中文语境中优越的推理能力。此外,对模型效率的进一步分析发现:多数推理能力优异的模型存在效率短板,而豆包1.5 Pro不仅推理表现突出,且模型效率较高,堪称兼顾推理能力与运行效率的标杆。过去半年,大语言模型(LLM)赛道出现了新拐点:价格战逐渐退潮,“推理能力”成为了新的主战场。从OpenAI的ol率先推出推理模型,到国产DeepSeek-R1因强大的解题能力冲上热搜,“谁能真正成为推理冠军?”成为用户最关心的问题。
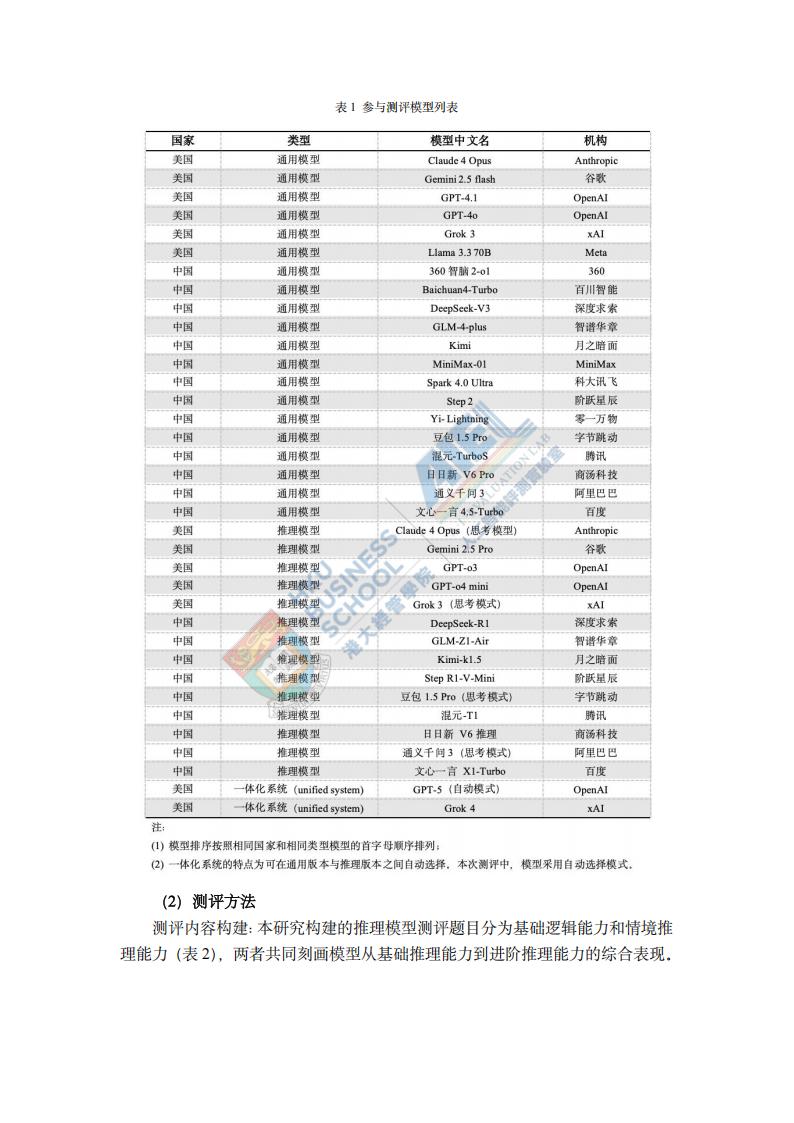
近日,香港大学经管学院蒋镇辉教授的人工智能评估实验室(AIEL)(https://hkubs.hku.hk/aimodelrankings/)公布了最新研究成果。该研究首次构建了涵盖基础逻辑与情境推理能力的综合测评体系(见图1)。实验室团队基于此精心设计了涵盖不同难度的测试集,并对中美两国36款主流LLM(包括14款推理模型、20款通用模型和2款一体化系统)进行了中文语境下的基准测试,全面揭示了不同模型在推理性能上的差异。测评结果显示:豆包1.5 Pro(思考模式)以93分的综合得分位居榜首,OpenAI近日推出的GPT-5(自动模式)紧随其后。整体而言,国产模型在推理能力方面展现了强劲实力。研究团队对近期中美两国发布的36个主流大语言模型开展了全面测试与评估(见表1)。由于受到本地部署的限制,Llama 4未被纳入本次测评。
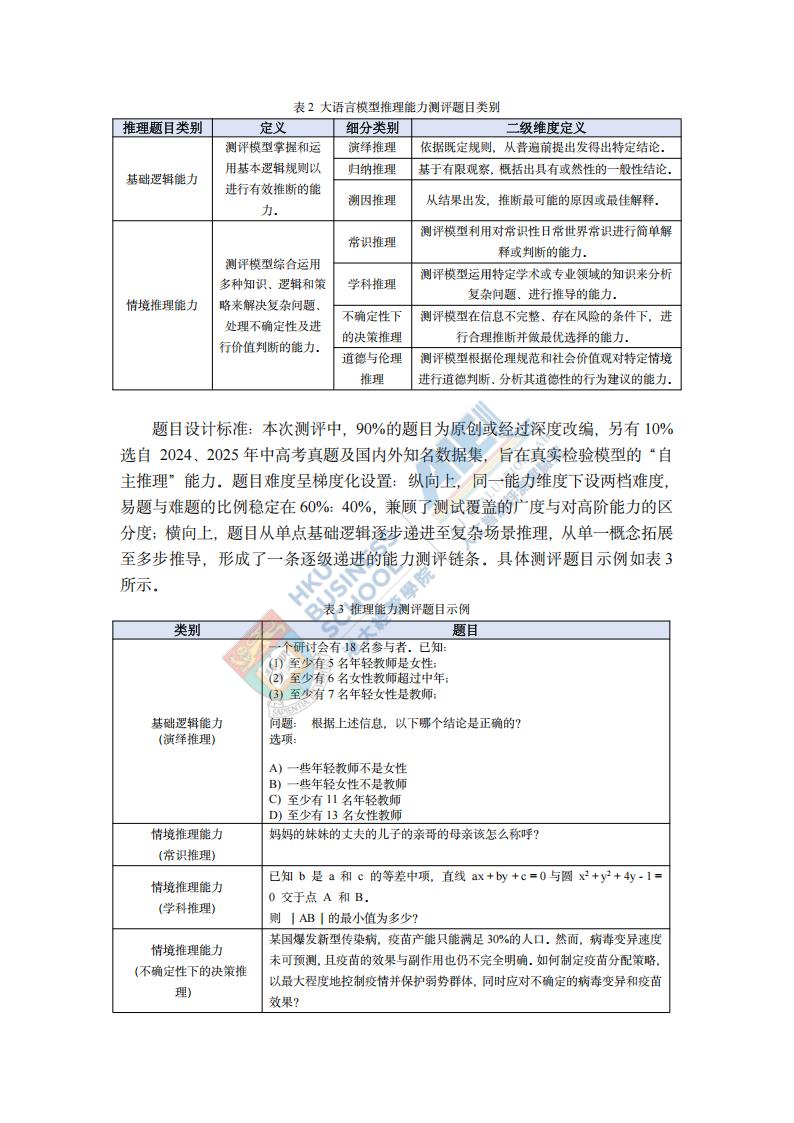
测评内容构建:本研究构建的推理模型测评题目分为基础逻辑能力和情境推理能力(表2),两者共同刻画模型从基础推理能力到进阶推理能力的综合表现。题目设计标准:本次测评中,90%的题目为原创或经过深度改编,另有10%选自2024、2025年中高考真题及国内外知名数据集,旨在真实检验模型的“自主推理”能力。题目难度呈梯度化设置:纵向上,同一能力维度下设两档难度,易题与难题的比例稳定在60%:40%,兼顾了测试覆盖的广度与对高阶能力的区分度;横向上,题目从单点基础逻辑逐步递进至复杂场景推理,从单一概念拓展至多步推导,形成了一条逐级递进的能力测评链条。具体测评题目示例如表3所示。

本文来自知之小站
报告已上传百度网盘群,限时15元即可入群及获得1年期更新
(如无法加入或其他事宜可联系zzxz_88@163.com)
