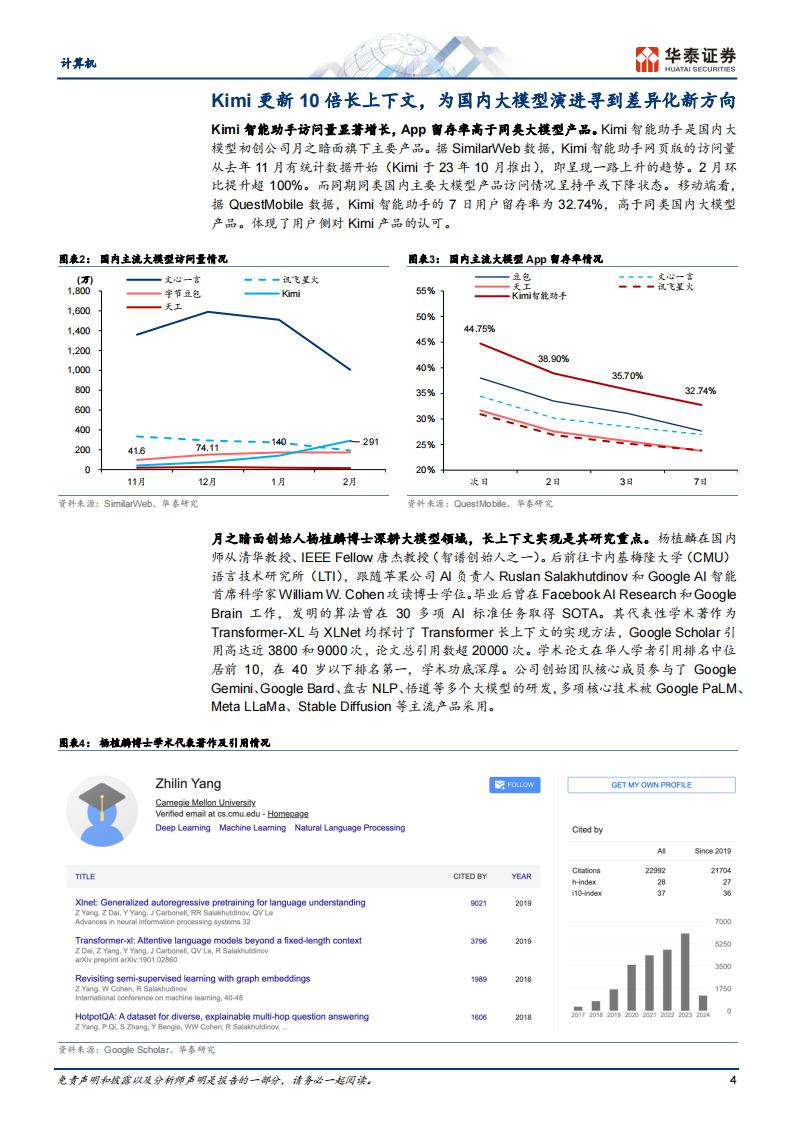
Kimi上下文长度10倍增长,引领国内大模型长上下文迭代新方向
大模型的长上下文支持能力已经成为重要的迭代方向。海外相对超前,Anthropic Claude 3模型标配200K上下文,并可向特定客户提供1M长度;Google Gemini 1.5 Pro标配支持1M上下文长度,内部已实现10M。国产大模型初创公司中,月之暗面的Kimi智能助手在23年10月即实现了20万字上下文,并在24年3月进一步迭代成为200万字。同月,阿里通义千问宣布文档解析功能支持1000万字;百度文心一言将在4月的更新中支持200万字以上的长文本能力;360智脑开始内测500万字长文本处理功能。长上下文已成为全球大模型迭代重要方向,关注其他国产模型厂商进展。
大模型长上下文,主要通过优化Transformer架构实现
目前,全球大模型仍然以Transformer解码器为主要架构基础。在此基础上,可以通过改进解码器架构来实现长上下文,主要改进方法包括:1)高效的注意力机制:降低计算成本,在训练时实现更长的序列长度,相应的推理时序列长度也就更长;2)实现长期记忆:设计显式记忆机制,以解决上下文
记忆的局限性。3)改进位置编码:对现有的位置编码进行改进,实现上下
文外推。4)对上下文进行处理:用额外的上下文预/后处理,确保每次调用中输入给LLM的输入始终满足最大长度要求。
国内大模型厂商可能采取了多种路线混合优化方法实现长上下文
长上下文作为核心技术,各厂商选择不公开。以月之暗面为例,其创始人杨植麟主要的学术论文Transformer-XL和XL-Net,均探讨了长上下文的实现方法,且前者属于长期记忆力的优化,后者属于特殊目标函数的优化。百度的ERNIE-Doc则同时采用了长期记忆力和特殊目标函数的优化方法。阿里Qwen-7B则使用了优化的位置编码算法extended RoPE。所以我们推测,国内模型厂商之所以能够在短期内实践出长上下文方法,或是在原有积累的基础上进行了算法迭代,采取多方法的混合优化,实现快速超车。
长上下文的通用性将解决多类场景需求,带来应用突破机会
具有长上下文的大模型通用性更强,用户将特定领域的知识通过上下文的方式输入到模型中,模型即可以通过上下文学习掌握相应内容,一定程度上代替模型的微调。此外,长上下文模型能适应虚拟角色的个性化信息记忆、开发者的长prompt输入、Al Agent的多轮调用需求,以及金融、法律等垂直客户长文档输入需求等多种场景,有望为Al+应用带来新的突破机会。
关注大模型长文本潜在受益产业链
长文本应用场景:1)文本工具:金山办公、福昕软件;2)法律文案:华宇
软件、通达海;3)业务流程:泛微网络、致远互联;4)其他文本:汉仪股份、汉王科技。专业领域+多任务+多模态场景:1)金融领域:同花顺、恒
生电子;2)医疗领域:嘉和美康;3)电商领域:光云科技。Al算力:浪潮信息、神州数码、海光信息。
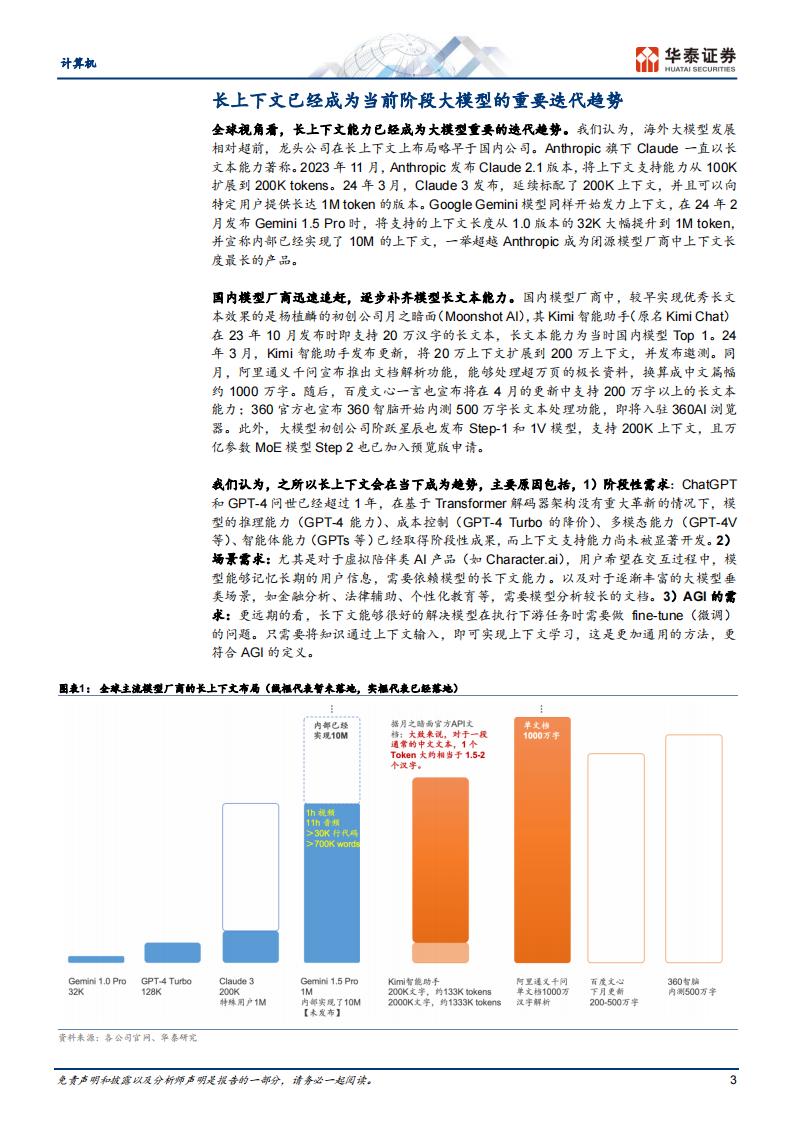
风险提示:宏观经济波动,技术进步不及预期。本研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。长上下文已经成为当前阶段大模型的重要迭代趋势
全球视角看,长上下文能力已经成为大模型重要的迭代趋势。我们认为,海外大模型发展相对超前,龙头公司在长上下文上布局略早于国内公司。Anthropic旗下Claude一直以长文本能力著称。2023年11月,Anthropic发布Claude2.1版本,将上下文支持能力从100K扩展到200K tokens。24年3月,Claude 3发布,延续标配了200K上下文,并且可以向特定用户提供长达1Mtoken的版本。Google Gemini模型同样开始发力上下文,在24年2月发布Gemini1.5 Pro时,将支持的上下文长度从1.0版本的32K大幅提升到1M token,并宣称内部已经实现了10M的上下文,一举超越Anthropic成为闭源模型厂商中上下文长度最长的产品。
国内模型厂商迅速追赶,逐步补齐模型长文本能力。国内模型厂商中,较早实现优秀长文本效果的是杨植麟的初创公司月之暗面(Moonshot Al),其Kimi智能助手(原名Kimi Chat)在23年10月发布时即支持20万汉字的长文本,长文本能力为当时国内模型Top 1。24年3月,Kimi智能助手发布更新,将20万上下文扩展到200万上下文,并发布邀测。同月,阿里通义千问宣布推出文档解析功能,能够处理超万页的极长资料,换算成中文篇幅约1000万字。随后,百度文心一言也宣布将在4月的更新中支持200万字以上的长文本能力;360官方也宣布360智脑开始内测500万字长文本处理功能,即将入驻360Al浏览器。此外,大模型初创公司阶跃星辰也发布Step-1和1V模型,支持200K上下文,且万亿参数MoE模型Step 2也已加入预览版申请。
我们认为,之所以长上下文会在当下成为趋势,主要原因包括,1)阶段性需求:ChatGPT和GPT-4问世已经超过1年,在基于Transformer解码器架构没有重大革新的情况下,模型的推理能力(GPT-4能力)、成本控制(GPT-4 Turbo的降价)、多模态能力(GPT-4V等)、智能体能力(GPTs等)已经取得阶段性成果,而上下文支持能力尚未被显著开发。2)场景需求:尤其是对于虚拟陪伴类Al产品(如Character.ai),用户希望在交互过程中,模型能够记忆长期的用户信息,需要依赖模型的长下文能力。以及对于逐渐丰富的大模型垂类场景,如金融分析、法律辅助、个性化教育等,需要模型分析较长的文档。3)AGl的需求:更远期的看,长下文能够很好的解决模型在执行下游任务时需要做fine-tune(微调)的问题。只需要将知识通过上下文输入,即可实现上下文学习,这是更加通用的方法,更符合AGl的定义。

本文来自知之小站
报告已上传百度网盘群,限时15元即可入群及获得1年期更新
(如无法加入或其他事宜可联系zzxz_88@163.com)
