引言
2022年11月30日,OpenAI推出ChatGPT。2025年1月20日,DeepSeek推出DeepSeek-R1模型。短短数年,大模型深刻地改变了科技发展方向,人类开始进入与AI共生的新时代。
2025年企业智能体(Agent)概念爆发,ChatBI,BiAgent,DataAgent等数据智能体概念逐步被大家熟知,获得了比较持续的企业关注热度,不少企业投入资源进行了验证性的尝试,更多的企业和数据架构师开始思考现有的大数据平台该如何进化,如何才能成为Ai-Ready的数据基础设施。
作为数据人,我们既站在AI的浪潮之始,也站在AI的悬崖边缘,不得不重新审视一切:当数据消费者从数据分析师转向数字分析师,数据生产方式将如何重构?当数据不止服务数据基员工,还要服务数据基员工,企业数据资产又将如何在AI时代释放价值?
本文结合国内外厂商在AI架构上的前沿探索,以及我们自身在数据能算体应用中的实践,从数据智能体的核心建设挑战入手,深入介绍和剖析连接大数据与大模型的 关键桥梁——数据语义层,并分享Aoudata基于NoEVT理念在这一领域的实践经验。
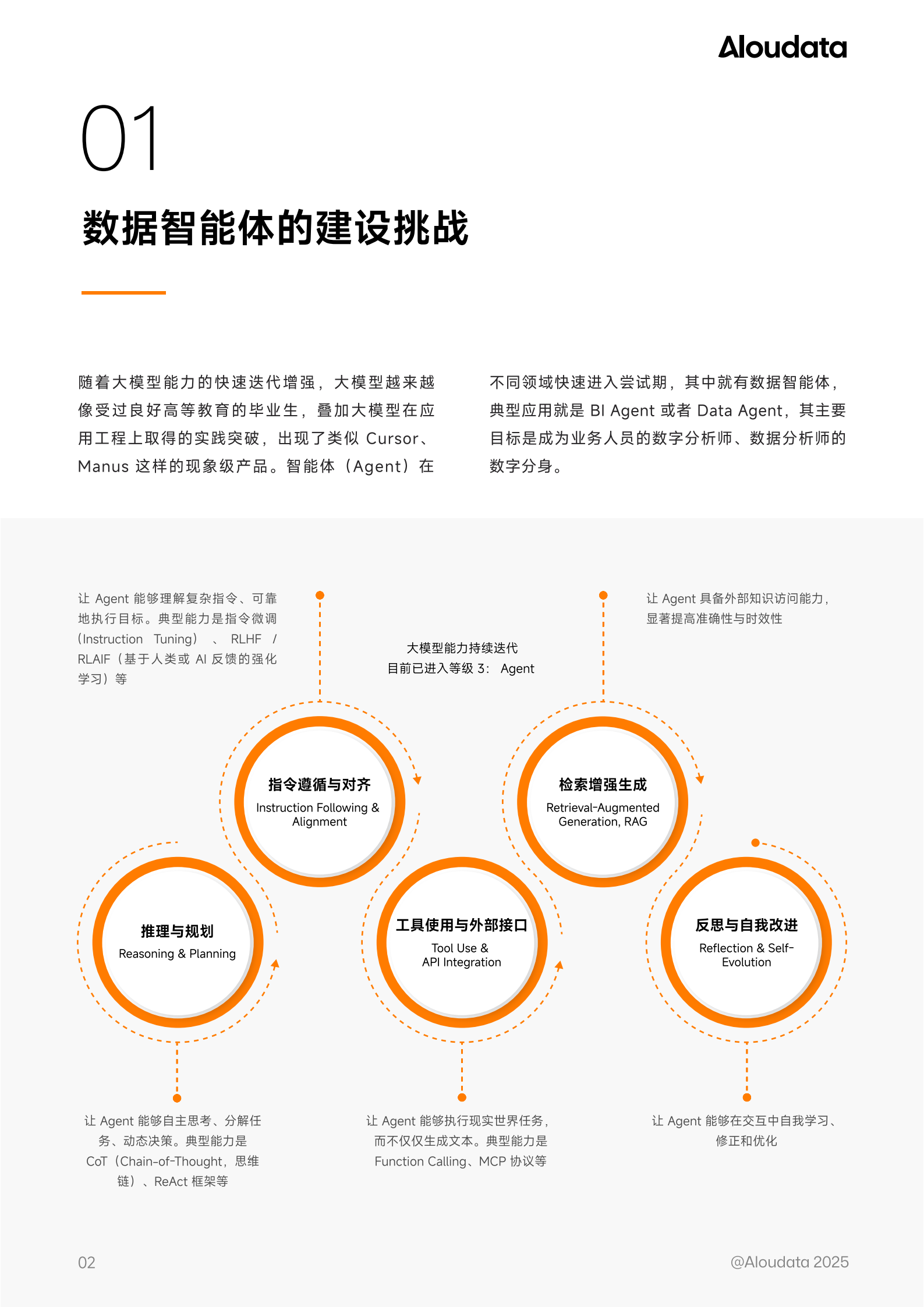
数据智能体的建设挑战
随着大模型能力的快速迭代增强,大模型越来越像受过良好高等教育的毕业生,叠加大模型在应用工程上取得的实践突破,出现了类似Cursor、Manus这样的现象级产品。智能体(Agent)在不同领域快速进入尝试期,其中就有数据智能体,典型应用就是BI Agent或者Data Agent,其主要目标是成为业务人员的数字分析师、数据分析师的数字分身。由于数据智能体具有“数字员工”的特性,我们在思考其建设挑战时,可以借鉴企业雇佣数据分析师的方式进行类比。
当企业招聘一名数据分析师时,往往需要提供岗前培训,内容包括行业术语、业务黑话、经营指标、业务流程和操作手册等。同样,当企业引入数据智能体(数字分析师)时,犹如引入陌生新员工(数字的),也需要向数据智能体“传授”相应的内部知识与业务规则。
在实际工作中,数据分析师需要在成千上万张表中找到符合取数口径的表和字段,生成正确的取数SQL,需要在业务人员与数据工程师之间频繁对数……,我们可以总结数据分析师经常会面临的两类典型挑战:


本文来自知之小站
报告已上传百度网盘群,限时15元即可入群及获得1年期更新
(如无法加入或其他事宜可联系zzxz_88@163.com)
