一、AI推理瓶颈迭代与架构演进,推动PCB价值定位跃升
1.1推理瓶颈从算力转向显存带宽,PCB成为AI系统性能关键承载者
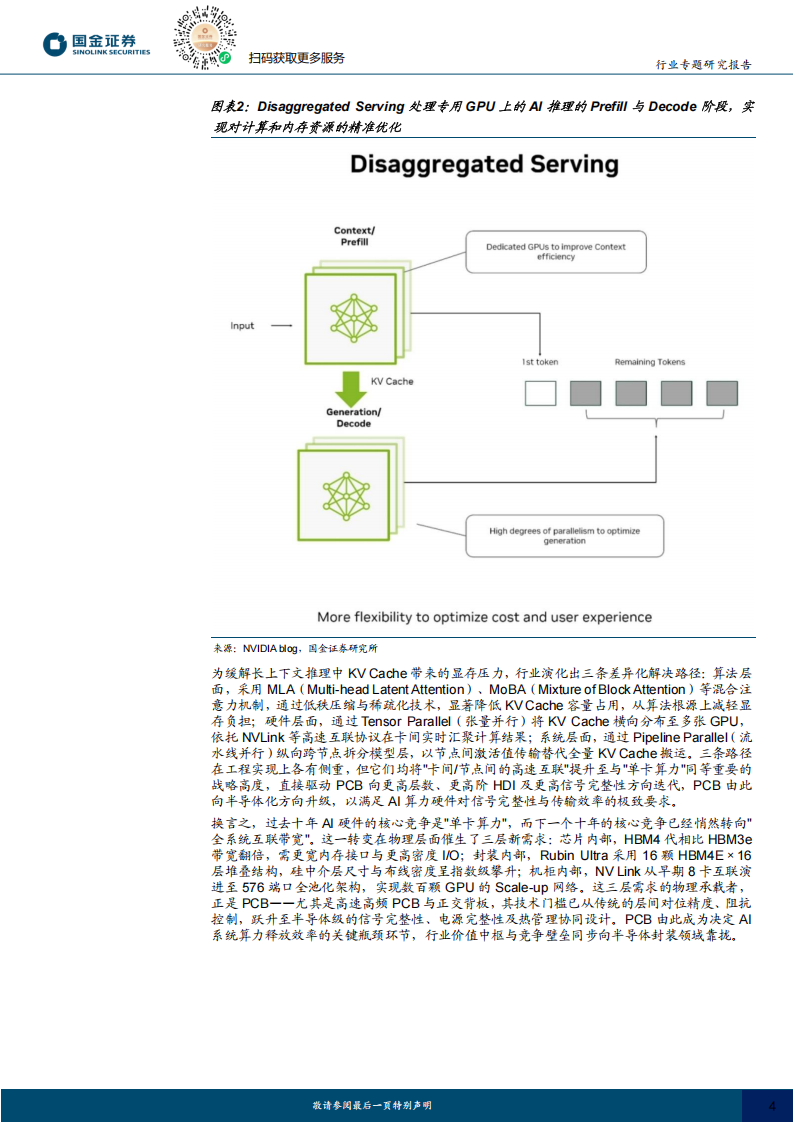
从Al计算底层物理特性来看,Transformer架构下大模型推理严格分为Prefill与Decode两个阶段,二者硬件资源消耗特征存在显著不对称,Prefill阶段为计算密集型,以矩阵-矩阵乘法(GEMM)为主,算术强度高,GPU可逼近FP4/FP8理论峰值性能,而Decode阶段为显存带宽密集型,以向量-矩阵乘法(GEMV)为主,需反复从HBM显存读取历史Key、Value向量至SRAM,算术强度大幅下降,Tensor Core长期处于等待数据的闲置状态,系统瓶颈由算力转向显存带宽,这种不对称性彻底重塑Al硬件设计哲学,推动PCB向高频高速、高密度互连、高层数、高精度方向升级,使其在材料、制程、精度上全面趋近半导体级标准,进而实现PCB“半导体化”,以匹配Al算力硬件对信号完整性、传输效率与系统稳定性的极致要求。这一阶段的资源消耗变化可以用一组数据直观呈现:在Prefill阶段,GPU算力利用率可达90%-95%,但显存带宽占用通常低于30%;而在长上下文Decode阶段(KVCache满载),GPU算力利用率可能降至20%-40%,显存带宽占用率则会升至85%-95%。这种算力与带宽的极端错配,正是英伟达在Rubin系列中推出”解耦式推理”(Disaggregated Inference)的核心动因——将Prefill与Decode拆分到不同硬件上,对Decode硬件大幅增加显存容量与互联带宽,对Prefill硬件保留高算力配置,通过硬件异构化实现资源的最优配置。这一架构变革对PCB提出了前所未有的要求:Decode节点需要更高密度的HBM显存封装基板与更高速的片间互联(NVLink/C2C),Prefill节点则需要支持更高功率密度的供电与散热方案,二者共同推动PCB从传统的连接载体升级为决定系统性能瓶颈的关键半导体级组件,技术门槛与客户认证周期已逼近半导体封装环节,行业属性由此发生根本性跃迁。为缓解长上下文推理中KV Cache带来的显存压力,行业演化出三条差异化解决路径:算法层面,采用MLA(Multi-head Latent Attention)、MoBA(Mixture of BlockAttention)等混合注意力机制,通过低秩压缩与稀疏化技术,显著降低KV Cache容量占用,从算法根源上减轻显存负担;硬件层面,通过Tensor Parallel(张量并行)将KV Cache横向分布至多张GPU,依托NVLink等高速互联协议在卡间实时汇聚计算结果;系统层面,通过Pipeline Parallel(流水线并行)纵向跨节点拆分模型层,以节点间激活值传输替代全量KVCache搬运。三条路径在工程实现上各有侧重,但它们均将”卡间/节点间的高速互联”提升至与”单卡算力”同等重要的战略高度,直接驱动PCB向更高层数、更高阶HDI及更高信号完整性方向迭代,PCB由此向半导体化方向升级,以满足AI算力硬件对信号完整性与传输效率的极致要求。
换言之,过去十年Al硬件的核心竞争是”单卡算力”,而下一个十年的核心竞争已经悄然转向”全系统互联带宽”。这一转变在物理层面催生了三层新需求:芯片内部,HBM4代相比HBM3e带宽翻倍,需更宽内存接口与更高密度I/O;封装内部,Rubin Ultra采用16颗HBM4E×16层堆叠结构,硅中介层尺寸与布线密度呈指数级攀升;机柜内部,NVLink从早期8卡互联演进至576端口全池化架构,实现数百颗GPU的Scale-up网络。这三层需求的物理承载者,正是PCB——尤其是高速高频PCB与正交背板,其技术门槛已从传统的层间对位精度、阻抗控制,跃升至半导体级的信号完整性、电源完整性及热管理协同设计。PCB由此成为决定Al系统算力释放效率的关键瓶颈环节,行业价值中枢与竞争壁垒同步向半导体封装领域靠拢。
1.2由芯片至机架架构演进,PCB从承载平台跃升为Al核心互联介质
我们沿着”芯片→封装→板卡→机架”的尺度由小到大,可以清晰地看到PCB在Al硬件中地位的演进。在芯片层面,HBM4的引入要求中介层和封装基板支持千位级I/O接口,信号完整性要求已逼近半导体封装基板标准;在封装层面,CoWoS-L向CoWoP的演进让PCB首次承担起类基板的功能,层间对位精度与线宽线距向先进封装看齐;在板卡层面,以GB300为例,服务器PCB层数从传统的10层左右跃升至20层以上,部分高端型号采用34至64层超高层设计,技术难度呈指数级攀升;而在机架层面,Rubin Ultra NVL576开始用一整块78层M9级正交背板取代铜缆,承担机柜内GPU的全互联通信,PCB由此从板级组件跃升为机架级核心互联介质。
机架架构的演进特别值得关注。随着单机柜内需支持多达数百颗GPU的全互联,传统的可插拔铜缆和光模块在弯曲半径、连接器占位和散热风道上正面临物理极限。为了在有限空间内实现计算托盘(Compute Tray)与交换托盘(Switch Tray)的高密度部署,业界正探索引入正交背板(Orthogonal Backplane)结构或共封装光学(CPO)技术,试图将原本依赖线缆的高速通道固化为板级互联。这相当于把一台AI服务器的机架级互联,从灵活的“线”升级为高度集成的“板”,标志着PCB开始从板级组件跃升为机架级核心互联介质。


本文来自知之小站
报告已上传百度网盘群,限时15元即可入群及获得1年期更新
(如无法加入或其他事宜可联系zzxz_88@163.com)
