OpenClaw是2025年末开源、2026年初在GitHub上爆炸式走红的本地优先(local-first)AI智能体(Agent)与自动化平台,由开发者Peter Steinberger发起,短短数月即累计二十多万Star,成为GitHub史上增长最快的开源项目之一。它的核心理念是让大模型从“对话式顾问”变成“真正能在本地动手干活的数字员工”,通过深度控制操作系统调用外部工具和在线服务,自动执行复杂任务。
OpenClaw因图标是红色龙虾,被广泛昵称为“龙虾”或“小龙虾”,同时受到产业界和广大用户广泛关注并积极实践应用,引发关于“养龙虾是否安全”的广泛讨论。工业和信息化部网络安全威胁和漏洞信息共享平台(NVDB)已发布专门预警,提示OpenClaw在不安全部署方式下存在较高安全风险,容易引发网络攻击和信息泄露。
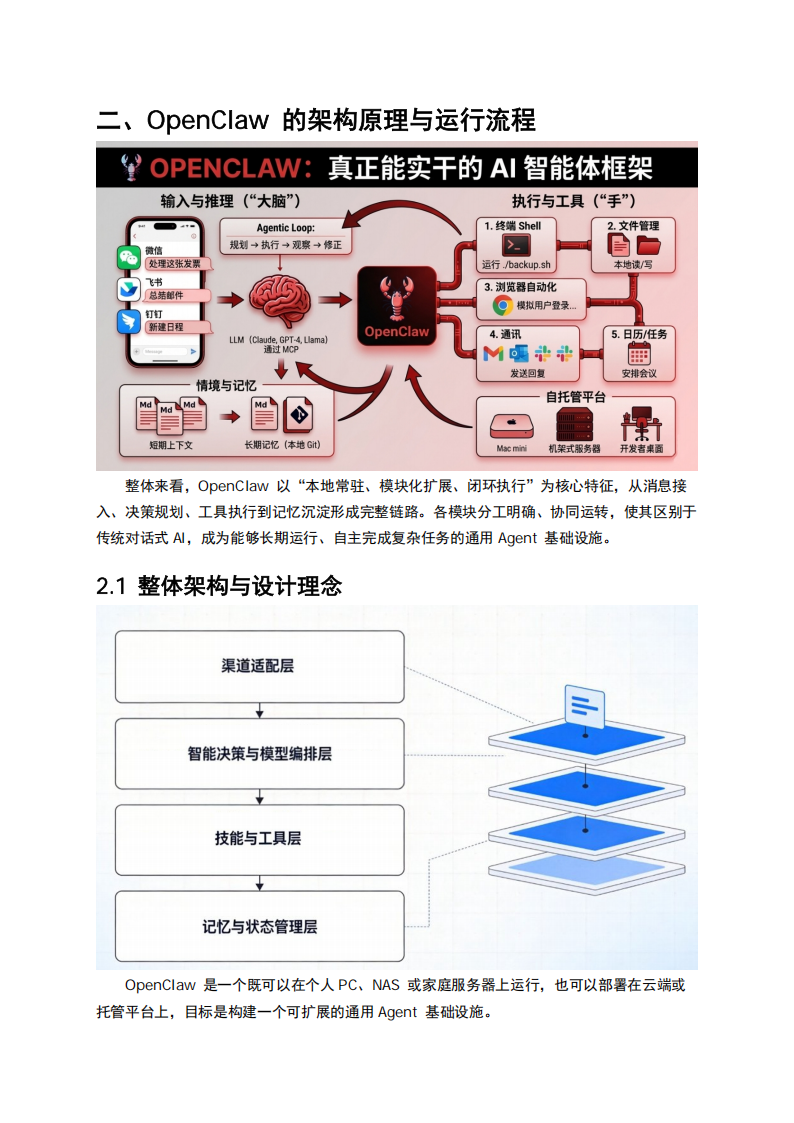
在这种背景下,有必要从体系结构与运行机理出发,系统梳理OpenClaw的工作流程、Skill机制与大模型交互特点,并对其已披露漏洞和系统性安全威胁进行分析,以为后续防护与治理提供技术依据。整体来看,OpenClaw以“本地常驻、模块化扩展、闭环执行”为核心特征,从消息接
入、决策规划、工具执行到记忆沉淀形成完整链路。各模块分工明确、协同运转,使其区别于
传统对话式AI,成为能够长期运行、自主完成复杂任务的通用Agent基础设施。OpenClaw是一个既可以在个人 PC、NAS 或家庭服务器上运行,也可以部署在云端或
托管平台上,目标是构建一个可扩展的通用Agent基础设施。其底层架构通常被拆解为四个核心模块:
·渠道适配层:通过网关对接WhatsApp、Telegram、Slack、Discord等聊天平台,
并可扩展到飞书、企业微信、邮件等,让用户在熟悉的沟通工具里直接和Agent交互。
·智能决策与模型编排层:对接不同大语言模型(LLM),负责会话管理、工具调用
决策、多步任务规划等,是“Agent大脑”。
·技能(Skills)与工具层:通过Skill插件和MCP工具扩展能力,实现浏览器自动
化、代码执行、文件操作、第三方SaaS集成等“动手能力”。
·记忆与状态管理层:利用Markdown文件和向量存储构建双层记忆系统(按天日志
+长期记忆),支撑长期个性化与复杂任务上下文管理。
整体上,OpenClaw通过“多通道接入+多模型编排+技能插件+本地记忆”构成一个可长期运行的常驻智能体,区别于传统只在浏览器里对话、没有持续状态的聊天机器人。OpenClaw官方定位为“你可以在自己设备上运行的个人AI助手”,支持在macOS、Linux、Windows桌面系统、树莓派等ARM设备及各类服务器上自托管部署。主流部署方式包括:
·个人电脑部署:通过npm或一键安装脚本在本地安装OpenClaw CLI,并将
Gateway注册为系统服务(macOS使用launchd,Linux使用systemd,Windows一般通过WSL2下的systemd),作为常驻后台网关进程运行。
·Docker/容器化部署:使用官方或社区提供的Docker镜像,映射容器内的
-1.openclaw目录以持久化配置和记忆,同时暴露18789等端口用于GatewayWeb控制台和API访问。·家庭服务器/NAS部署:在家用服务器或NAS上运行OpenClaw,通过内网或穿透
工具(如Localtonet)实现远程访问,也可以在多台设备上分别部署Gateway,由不同节点承担不同类型的任务。
从安全视角看,本地部署的优势在于数据安全:对话记录、文件内容、API凭证等敏感信息都保存在用户自己的机器上,不必上传到第三方云平台。但相应地,系统加固、访问控制、备份和更新等责任也全部落在用户或运维团队自身身上,一旦配置不当反而更容易暴露于互联网攻击面。
2.3模型支持:本地模型与云端模型
OpenClaw的模型编排层支持接入多种云端大模型(如OpenAI GPT系列、AnthropicClaude、Google Gemini等)以及本地部署的开源模型(如通过Ollama或本地推理服务运行的Llama系列),用户可以在配置中选择首选模型和备选模型,并为不同任务设置不同的模型策略。
·本地模型:通过在本机或局域网部署Llama等模型推理服务,OpenClaw可以完全
在本地完成推理,不把任何prompt、历史对话或文件内容发到云端,从而在隐私上最可控,但生成质量和推理速度依赖本地硬件和模型能力,复杂任务可能受限。
·云端模型:通过统一API网关(如OpenRouter/APIYI等)或直接使用
OpenAl/Anthropic官方接口,OpenClaw可以调用性能更强、能力更全面的商业模型,用于代码生成、复杂推理、多模态处理等高难度任务,但需将指令和上下文发送至云端,存在数据出境和隐私泄露风险。
实践中,不少教程建议采用“混合策略”:对隐私要求极高或逻辑简单的任务优先使用本地模型,对需要高智能或多模态能力的场景则路由到云端高阶模型;同时结合记忆压缩/蒸馏、把常用流程固化为Skill,以及为不同子任务配置更便宜的模型,以减少昂贵模型的token消耗和API成本。
2.4与大模型的API交互与Token消耗
OpenClaw在逻辑上是一个“模型客户端+执行协调器”,与大模型的交互主要通过HTTPAPI完成,采用OpenAl/Anthropic等主流的Chat Completion或Tool Calling接口。每次调用需要将系统提示词、项目上下文(如AGENTS.md、SOUL.md)、对话历史、当前消息以及相关记忆片段等内容打包发送给大模型,从而实质上消耗大量Token。
典型的上下文构成包括:系统Prompt、项目配置上下文(AGENTS.md、SOULmd等)、对话历史与工具调用记录、当前用户输入及检索到的记忆内容,这些内容合计可能达到数万Token。因此,社区出现了记忆蒸馏、对话压缩、模型降级等优化方案,通过预压缩写入MEMORY.md、使用更便宜的模型完成部分子任务,已有案例将单轮上下文从一万三千多Token压缩到约六千多Token,节省约一半的Token成本。


本文来自知之小站
报告已上传百度网盘群,限时10元即可加入
(如无法加入或其他事宜可联系zzxz_88@163.com)