在当今的技术栈中,这个角色的最佳选择,几乎被VIT(VisionTransformer)及其变体所垄断。而VIT的强大,又来自于其特定的“预训练”方式。
VLA领域最受青睐的ViT主要有两种:CLIP/SigLIP和DINov2
1.CLIP/SigLIP:提供“内容识别”能力(“What is it?”).核心功能:CLIP(及其优化版SigLIP)的核心是强大的视觉-文本对齐(visual-text alignment)能力。它擅长将图像中的像素与描述这些像素的自然语言单词联系起来。
·训练方式:它们通过海量的“图像-文本”配对数据进行
“对比学习”(Contrastive Learning)。简单来说,它们学习到了“这段文字描述的就是这张图片”。
.SigLIP的优势:SigLIP是CLIP的直接升级版。它用更简单、扩展性更好的Sigmoid损失函数,取代了CLIP复杂的Softmax损失函数,训练过程更高效,且在更大规模数
据集上表现更好,从而实现了“更简单,效果更好”。
.VLA中的角色:SigLIP主要为VLA提供了“识别和描述图像内容”的能力。它负责告诉“大脑”:“我看到了一个红色的瓶子”或“这是一条狗,脖子上有牵引绳”。
2.DINOv2:提供“空间理解”能力(“Where is it?How is it positioned?”)核心功能:DINOv2的核心是强大的空间理解和高级视觉语义能力。训练方式:它是一种自监督学习(Self-Supervised Learning)模型。它不需要文本标签,而是通过一种名为“自蒸馏”(self-distillation)的方式进行训练。这种方式强迫模型去理解图像的内在空间结构(例如,一张猫的左耳和右耳在空间上的关系,即使没有任何文字告诉它这是“猫”或“耳朵”)。
VLA中的角色:DINOv2主要为VLA提供了“空间推理能力”。它负责告诉“大脑”:
“那个红色的瓶子在碗的左边,并且是竖立着的”,或者“那只狗正坐着,它的牵引绳延伸到了草地上”。
视觉编码器(V):VLA的“眼睛”
VLA领域最受青睐的ViT主要有两种:CLIP/SigLIP和DINOv2
3.顶尖方案:SigLIP+DINOv2双编码器
1.并行编码:原始图像被同时输入到SigLIP和DinoV2两个独立的视觉编码器中。
2.特征提取:SigLIP输出包含丰富“内容”信息的特征向量,DinoV2输出包含精确“空间”信息的特征向量。
3.特征融合:这两种不同类型的特征向量在通道维度上被“连接”(Concatenated)在一起,形成一个同时包含“是什么”和“在哪里/怎么样”的“综合性的视觉表示”(comprehensive visual representation)。
4.模态对齐-关键步骤:最后,这个“综合视觉特征”必须被“翻译”成“大脑”(L模块,即LLM)能够理解的“语言”。这个关键的“翻译”步骤由一个MLP Projector(多层感知机投影器)完成。该投影器负责将高维的视觉特征向量,投影(映射)到与LLM处理文本时使用的相同的“令牌”(Token)嵌入空间中。
通过这种“双编码器+MLP投影器”的精密设计,VLA的“眼睛”就为“大脑”提供了最完美的输入:一个既知道“是什么”(来自SigLIP),也知道“在哪里/怎么样”(来自DinoV2)的、且“大脑”能够直接理解的视觉信息流。
理想汽车MindVLA的实现方式:拥抱3D高斯建模(3DGS)
MindVLA的V模块核心是:
1.3D高斯建模-3D Gaussian Splatting,3DGS:它没有使用SigLIP或DINOv2,而是直接采用了基于3D高斯球的场景表示方法。这种方法旨在从多视图2D图像中,重建出更精细、更连续的3D场景。
2.自监督3D编码器预训练-Self-Supervised 3D Encoder Pretraining:其V模块通过自监督的方式,直接从传感器数据(包括摄像头Cameras,激光雷达Lidar等)通过3D Encoder生成统一的SceneRepresentation(场景表示)。
3D Tokenizer /3D Projector:最终,这个基于3DGS的场景表示,通过3D Projector(3D投影器)或3D Tokenizer被转换为MindGPT(L模块)可以理解的Token。
对比总结:
·通用方案-SigLIP+DINOv2:更侧重于从2D图像中提取内容和空间语义,并通过MLP投影器与
LLM对齐。
.MindVLA方案-3DGS:更侧重于直接进行高保真的3D场景重建,为“从零预训练”的L模块提供更原生、更丰富的3D空间输入。
这两种不同的V模块实现路径,也反映了VLA架构仍在快速发展,不同的团队在根据自身的技术积累和目标进行着不同的探索。

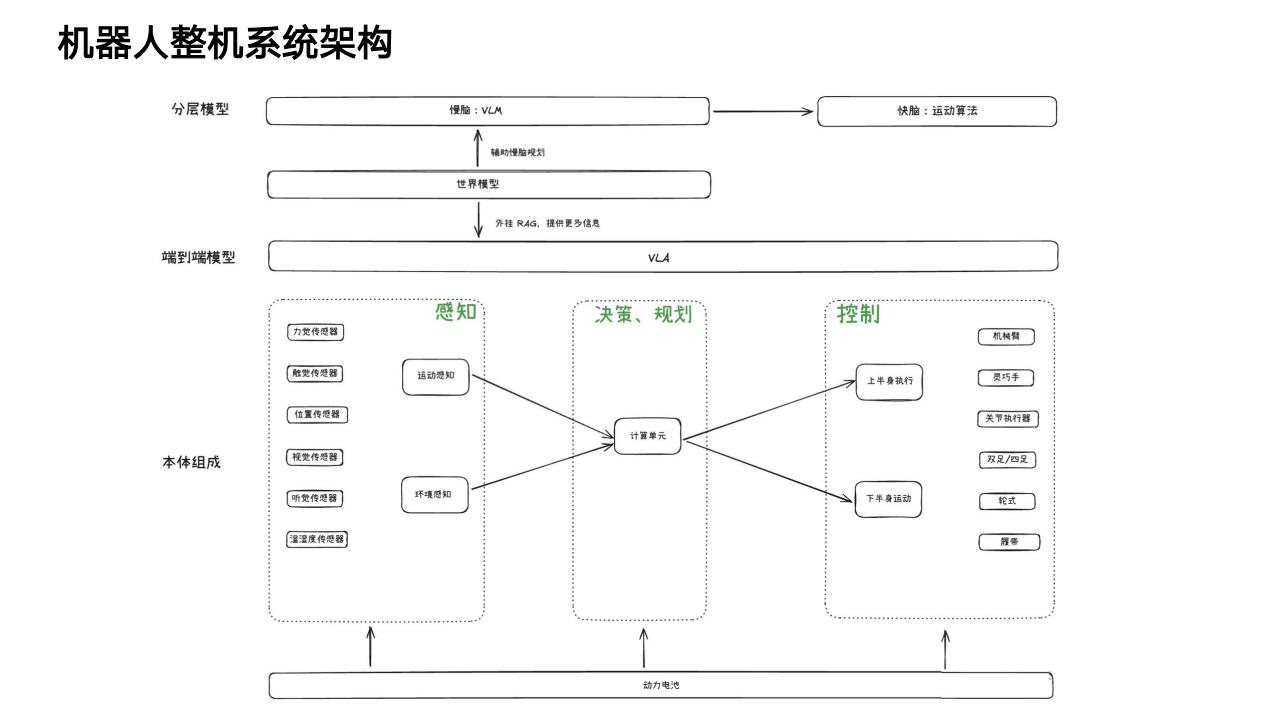
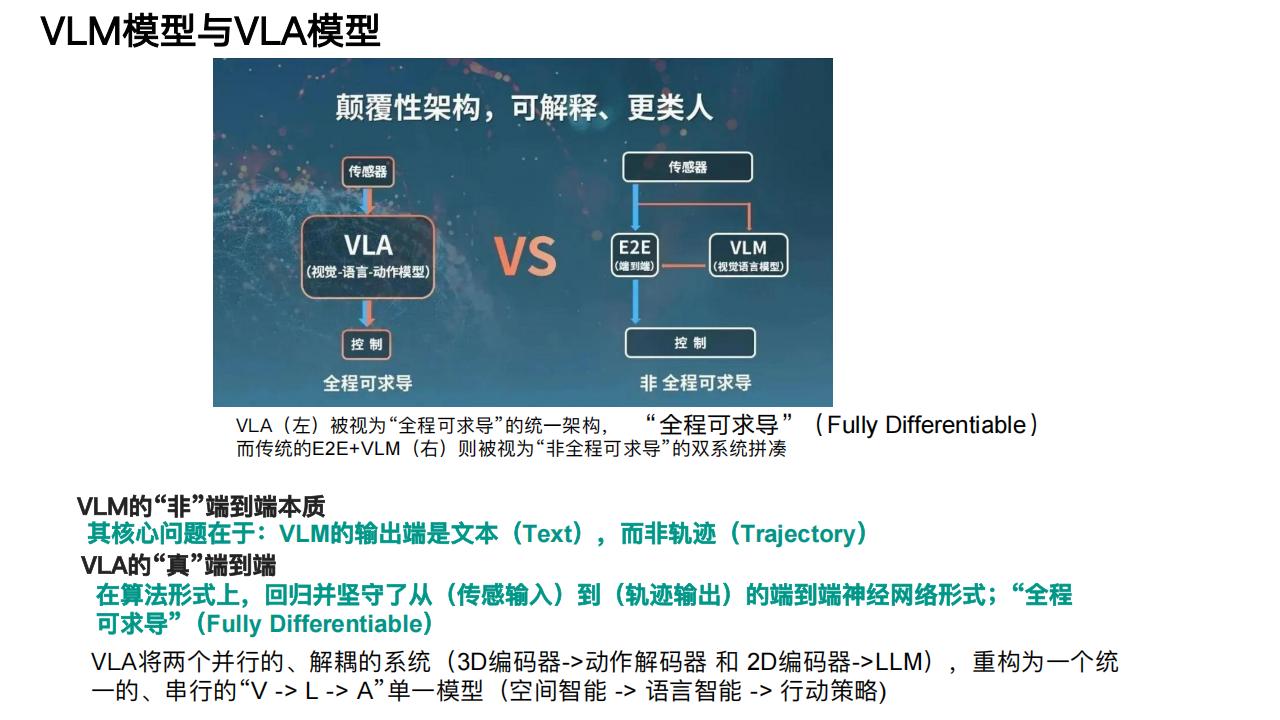
本文来自知之小站
报告已上传百度网盘群,限时15元即可入群及获得1年期更新
(如无法加入或其他事宜可联系zzxz_88@163.com)
